- News and Stories
- Blog post
- Principles & Practices
How We Built Our AI Application to Handle PDFs

The federal government has officially told state and local governments: it’s time to tackle web accessibility issues. Things like meeting notes, legislative documents, forms, and maps are everywhere on government websites, often in inaccessible file formats. By 2026, that web content must meet WCAG 2.1 AA accessibility standards, which means that millions of files on government websites across the country will need to be updated, with PDFs as a primary obstacle.
That’s why we built an AI-enabled web application that makes PDF audits easier by gathering all PDFs in one place and providing ways to search and filter their documents. We combined large language models (LLMs) and traditional machine learning techniques to enable government staff to make decisions on how to deal with their PDFs.
At Code for America, we advocate for an approach that embraces the opportunities within new technologies while using a responsible, iterative, and evaluative approach. This was a guiding factor as we built the tool and informed two vital elements of the project: picking the right tool for the job and creating a holistic LLM evaluation framework.
Evaluating LLMs for the right fit
LLMs like ChatGPT or Claude have opened up new possibilities to support how we understand digital content, such as summarizing challenging concepts and analyzing images. As with any new promising technology, we wanted to be intentional with how we added LLMs to our toolkit. We employed a framework where we considered both the simplest effective solution and turned to LLMs and their unique advantages to solve more complex problems.
First, we focused on our data sources. Our tool focuses on documents that are publicly available, meaning we had a broad range of data for LLM application in a low-risk setting. We then considered the potential for inconsistency and bias. LLMs can reproduce the tendencies of the data that they’re trained on and can produce unexpected output. But these concerns are not insurmountable and can be addressed through continuous and robust evaluation processes. In fact, LLMs can be employed effectively for this evaluation.
Of course, no technology is without tradeoffs. Effective LLM deployment includes API management and runtime expenses. These costs should be weighed against the limitations and brittleness of rule-based systems or the resources needed to maintain manual workflows. For the right tasks, LLMs open up the space of possibilities to tackle technical problems in ways that weren’t possible even a short time ago.
Finding spaces for traditional machine learning
When we started this project, we knew we wanted to build a tool to help governments understand both the scale of their PDF problems and where to start. After scraping stakeholder websites and extracting metadata, we needed to classify the documents by category. Our subject matter expert provided us with thousands of labeled documents and a list of a dozen groups like: brochure, form, or policy. Sorting thousands of documents into categories is not an ideal problem for a purely prescriptive rule-based approach, nor was there an off-the-shelf solution that met our needs. Our next step was to assess traditional machine learning techniques that could help.
Based solely on data around the documents like URL, keywords near the originating link, and file name, we were able to use an algorithm called XGBoost to accurately classify documents into categories 81% of the time. This approach generated good results, while avoiding the extra complexity of extracting content from the documents or using an expensive API call to an LLM.
Combining these tools to make an app that provides the most value
When stakeholders use the web app, we wanted to provide them with a suggestion on how to handle a given document. There are five options: remediation, conversion, archival, removal, or exception. Remediation encompasses tagging headers, tables, lists, and more on PDFs and setting their reading order, as well as defining alt text for images and document properties like an informative title—it’s expensive and time consuming. Oftentimes it makes more sense to convert a document to html, archive it, or remove it.
The federal ruling provides four criteria that exempt a document from compliance. Whether or not these four exceptions apply for a given document is a complex and contextual problem. We found the problem could not be solved by rule-based programming approaches, off-the-shelf solutions, or traditional machine learning approaches, especially given our lack of labeled data. In this circumstance, an LLM integration made a lot of sense.

With an LLM, we compare a document with ADA policy to evaluate whether an exception applies.
Evaluating our LLM for quality and consistency
Once an LLM integration is identified as the best solution, investing in a framework to evaluate quality and consistency over time is imperative. This is the only way to unearth bias and keep random or bad responses in check. There is a burgeoning field of LLM-as-judge evaluation frameworks that can assess the quality of outputs where there is no single correct answer. The frameworks provide prompt scaffolding to ask an LLM “judge” to evaluate LLM-generated responses for facets like faithfulness (hallucination), relevancy, helpfulness, or toxicity.
An LLM-as-judge approach has its difficulties—for example, it can introduce more bias. But it’s difficult to assess LLM behavior via manual or traditional machine learning-based means alone. To evaluate an LLM, sometimes you need an LLM.
So in a situation like that, to mitigate the risk of more bias being introduced, we use a funnel-based evaluation approach. By that, we mean evaluating the most qualitative and quantitative data points possible. We combine traditional programming approaches like word searches to make sure certain facts are included in the response, and specialized metrics to compare AI-generated summaries with curated human-created summaries and LLM-as-judge evaluations. We think of it less as an automated testing suite and more of a window into the solution we are creating. We think this porthole will come in handy as we iterate on prompts or consider swapping out models.
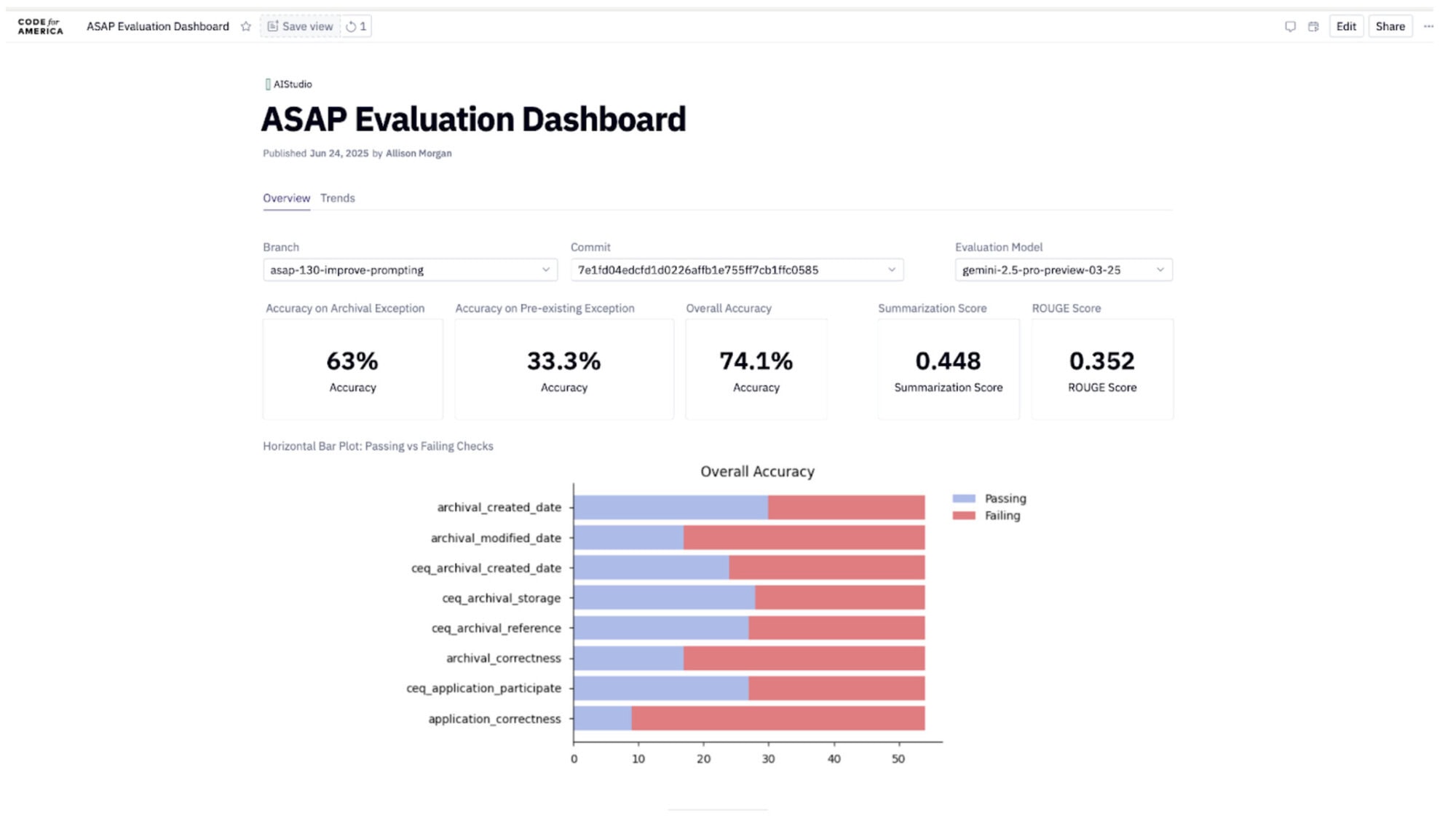
Example dashboard for monitoring LLM quality and consistency.
Embracing the possibilities and challenges of AI
Our goal at Code for America is to enable government to embrace emerging technologies in an ethical, human-centered way. This philosophy was reflected in the steps we took on this project to evaluate when to use an LLM, how to integrate traditional AI/machine learning methods, and how to evaluate our system to check for accuracy and consistency. With this tool, we’re showing that you can build AI solutions that boost government efficiency to solve real problems in a human-centered way.
Interested in improving web accessibility, or want to have a conversation with the AI Studio team about the AI use cases you’re considering? Reach out to us.